
On May 21st and 22nd, I had the honor of having been chosen to attend the rOpenSci unconference 2018 in Seattle. It was a great event and I got to meet many amazing people!
rOpenSci rOpenSci is a non-profit organisation that maintains a number of widely used R packages and is very active in promoting a community spirit around the R-world. Their core values are to have open and reproducible research, shared data and easy-to-use tools and to make all this accessible to a large number of people.
Registration is now open for my 1.5-day workshop on deep learning with Keras and TensorFlow using R.
It will take place on July 5th & 6th in Münster, Germany.
You can read about one participant’s experience in my last workshop:
Big Data – a buzz word you can find everywhere these days, from nerdy blogs to scientific research papers and even in the news. But how does Big Data Analysis work, exactly?

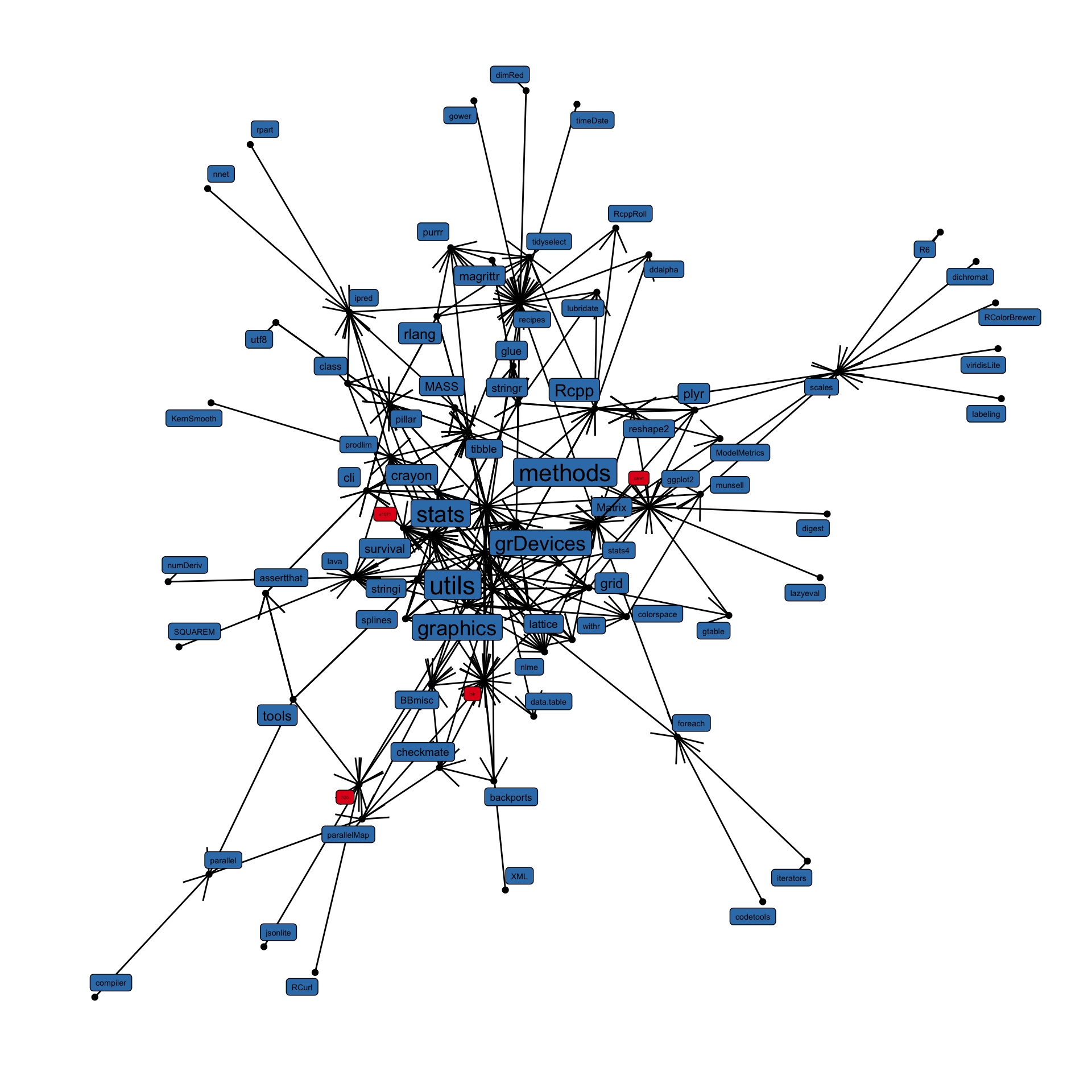
When looking through the CRAN list of packages, I stumbled upon this little gem:
pkgnet is an R library designed for the analysis of R libraries! The goal of the package is to build a graph representation of a package and its dependencies.
And I thought it would be fun to play around with it. The little analysis I ended up doing was to compare dependencies of popular machine learning packages.
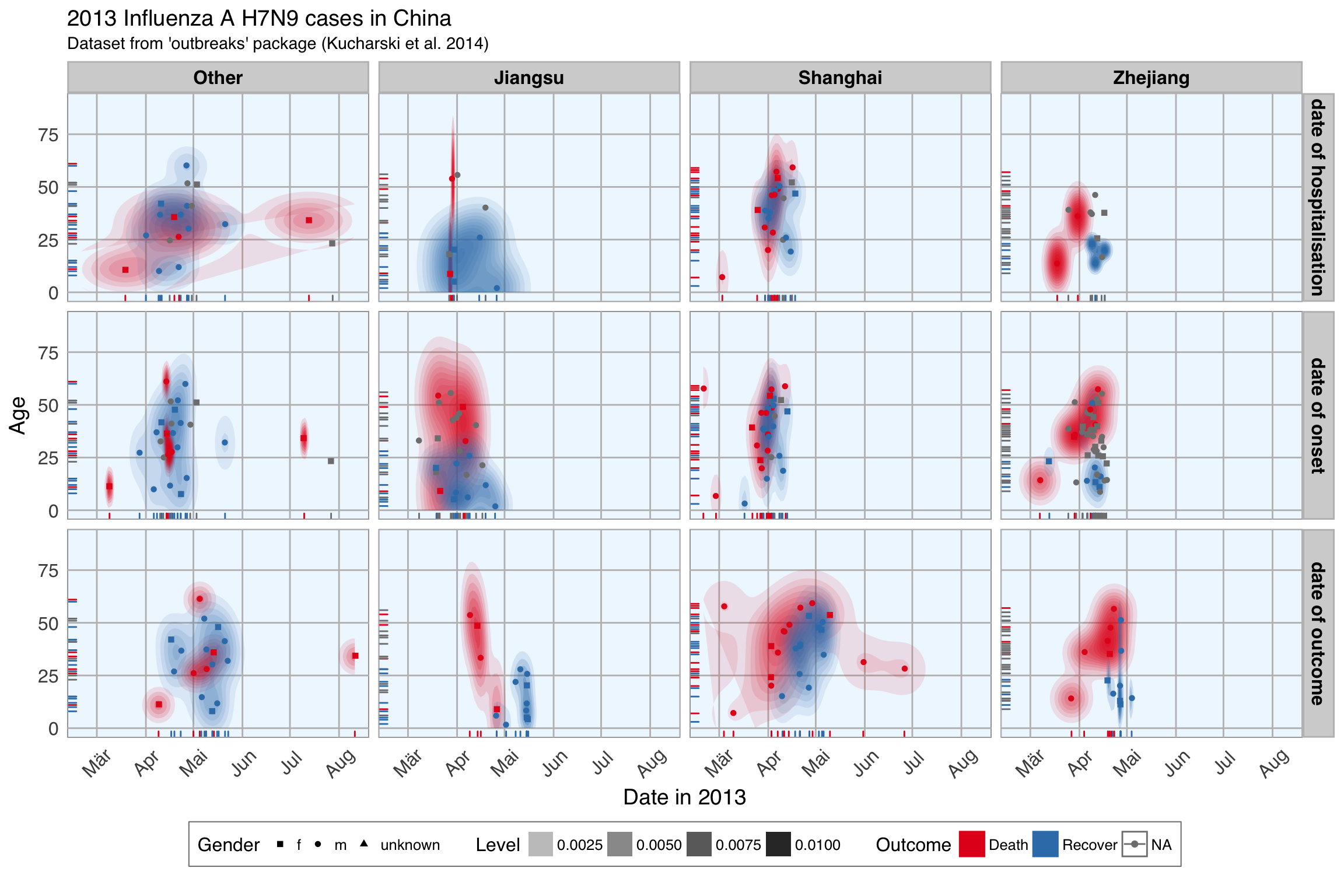
Since I migrated my blog from Github Pages to blogdown and Netlify, I wanted to start migrating (most of) my old posts too - and use that opportunity to update them and make sure the code still works.
Here I am updating my very first machine learning post from 27 Nov 2016: Can we predict flu deaths with Machine Learning and R?. Changes are marked as bold comments.
The main changes I made are:
In our next MünsteR R-user group meetup on Monday, June 11th, 2018 Thomas Kluth and Thorben Jensen will give a talk titled Look, something shiny: How to use R Shiny to make Münster traffic data accessible. You can RSVP here: http://meetu.ps/e/F7zDN/w54bW/f
About a year ago, we stumbled upon rich datasets on traffic dynamics of Münster: count data of bikes, cars, and bus passengers of high resolution. Since that day we have been crunching, modeling, and visualizing it.
On April 12th, 2018 I gave a talk about Explaining complex machine learning models with LIME at the Hamburg Data Science Meetup - so if you’re intersted: the slides can be found here: https://www.slideshare.net/ShirinGlander/hh-data-science-meetup-explaining-complex-machine-learning-models-with-lime-94218890
Traditional machine learning workflows focus heavily on model training and optimization; the best model is usually chosen via performance measures like accuracy or error and we tend to assume that a model is good enough for deployment if it passes certain thresholds of these performance criteria.

On April 4th, 2018 I gave a talk about Deep Learning with Keras at the Ruhr.Py Meetup in Essen, Germany. The talk was not specific to Python, though - so if you’re intersted: the slides can be found here: https://www.slideshare.net/ShirinGlander/ruhrpy-introducing-deep-learning-with-keras-and-python
Ruhr.PY - Introducing Deep Learning with Keras and Python von Shirin Glander There is also a video recording of my talk, which you can see here: https://youtu.

