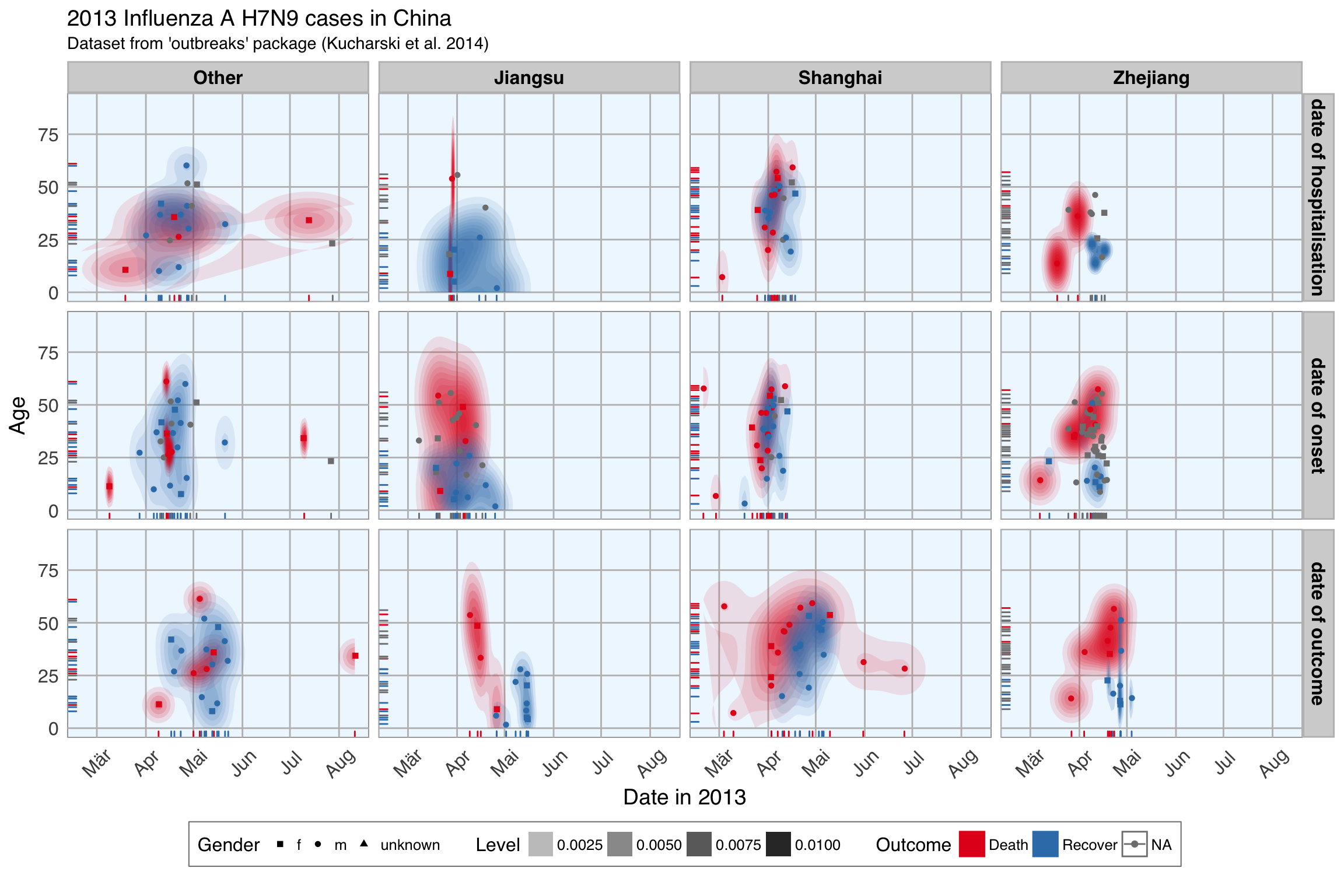
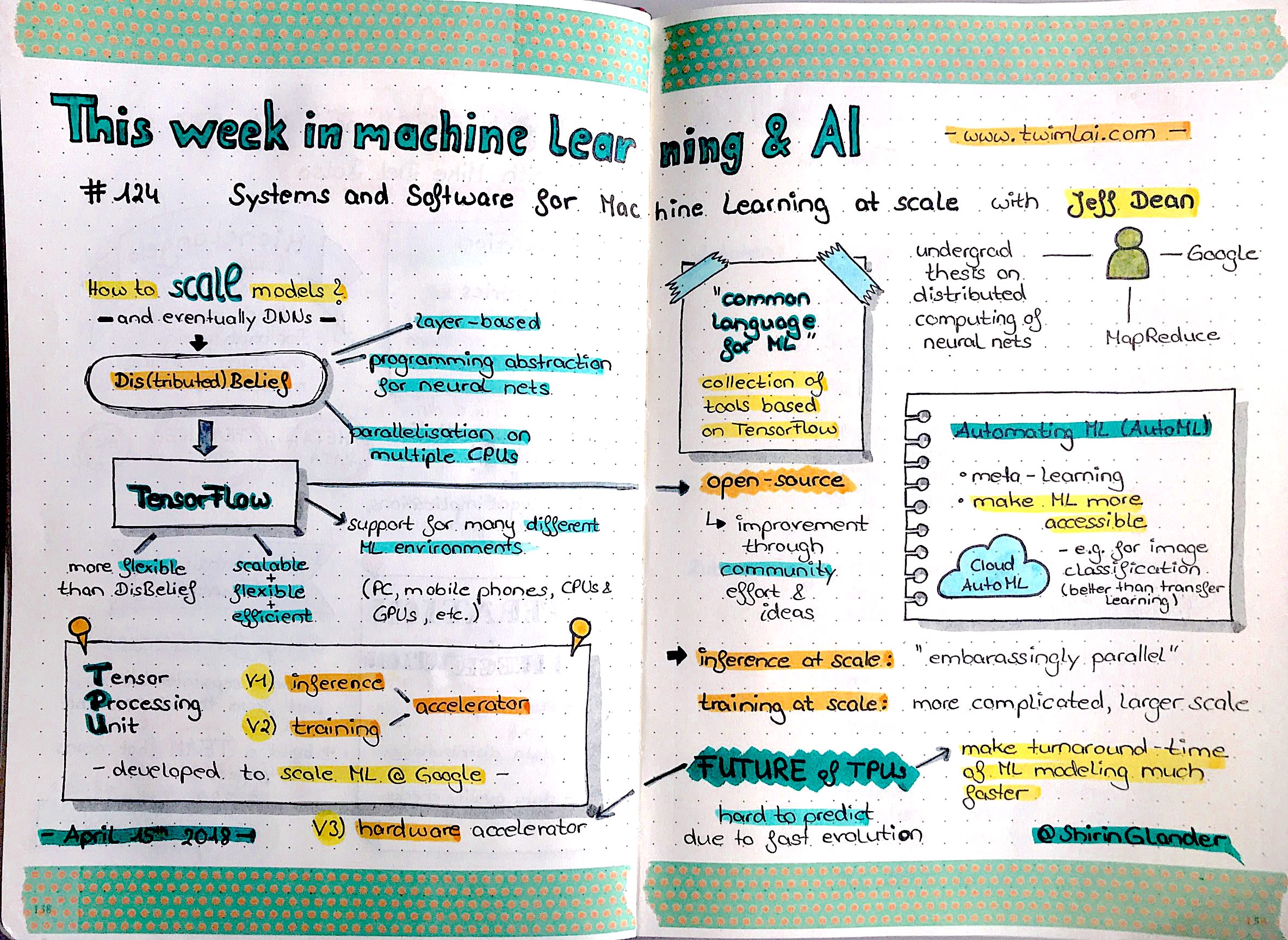
Here I am sharing the slides for a talk that my colleague Uwe Friedrichsen and I gave about Deep Learning - a Primer at the JAX conference on Tuesday, April 24th 2018 in Mainz, Germany.
Slides can be found here: https://www.slideshare.net/ShirinGlander/deep-learning-a-primer-95197733
Deep Learning is one of the “hot” topics in the AI area – a lot of hype, a lot of inflated expectation, but also quite some impressive success stories.