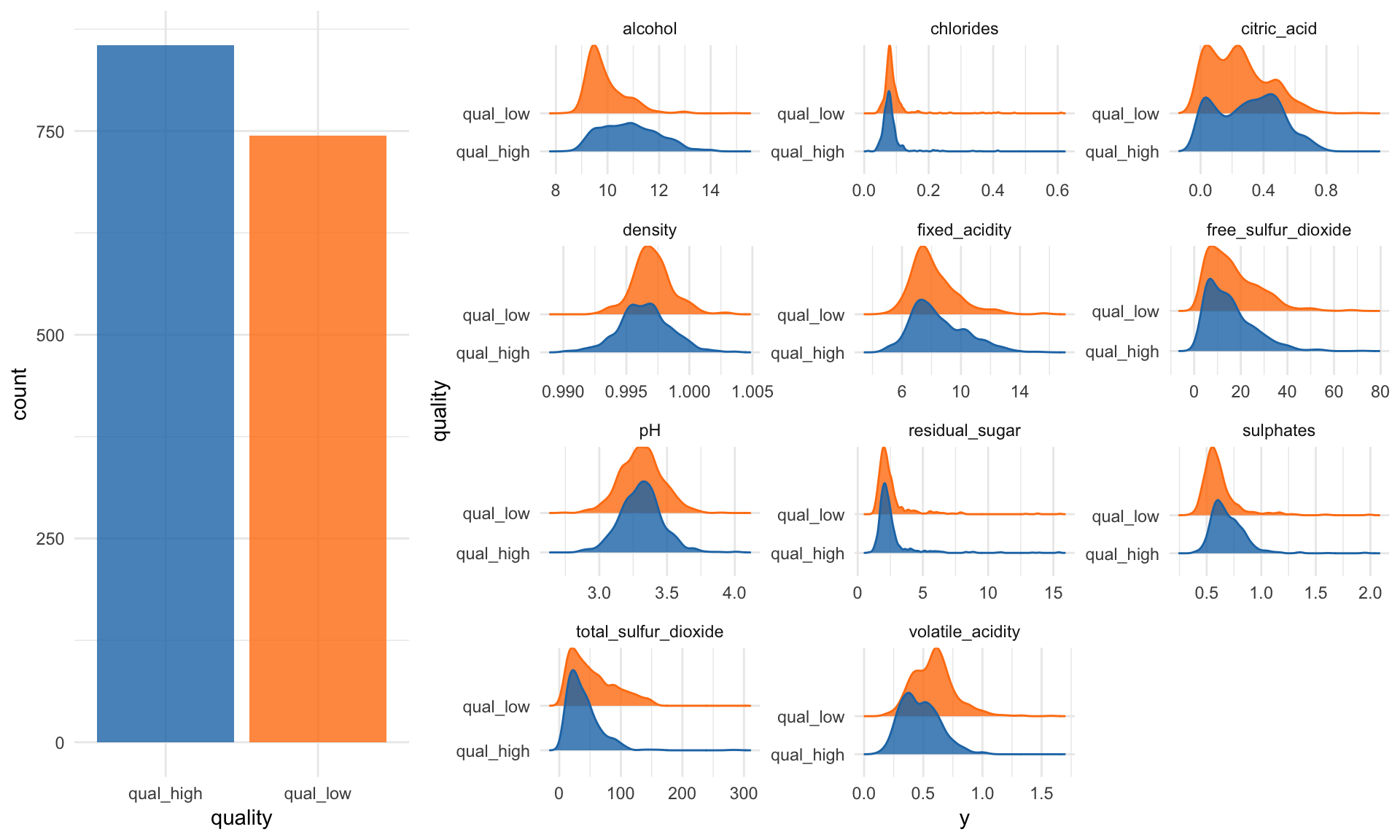
This is code that will encompany an article that will appear in a special edition of a German IT magazine. The article is about explaining black-box machine learning models. In that article I’m showcasing three practical examples:
Explaining supervised classification models built on tabular data using caret and the iml package Explaining image classification models with keras and lime Explaining text classification models with xgboost and lime